publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
-
 Character Attribute Extraction from Movie Scripts Using LLMsSabyasachee Baruah, and Shrikanth NarayananIn ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
Character Attribute Extraction from Movie Scripts Using LLMsSabyasachee Baruah, and Shrikanth NarayananIn ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024Narrative understanding is an integrative task of studying characters, plots, events, and relations in a story. It involves natural language processing tasks such as named entity recognition and coreference resolution to identify the characters, semantic role labeling and argument mining to find character actions and events, information extraction and question answering to describe character attributes, causal analysis to relate different events, and summarization to find the main storyline. In this work, we aim to formally operationalize the task of character attribute extraction, motivated by analyzing inclusive character representations and portrayals. We focus on a mix of static and dynamic attribute types that require varying context sizes for their accurate retrieval. We use automated screenplay parsing, entity recognition, and external knowledge bases to collect character descriptions from movie scripts, and explore different prompting strategies (zero-shot, few-shot, and chain-of-thought) to leverage large language models for attribute extraction.

2023
-
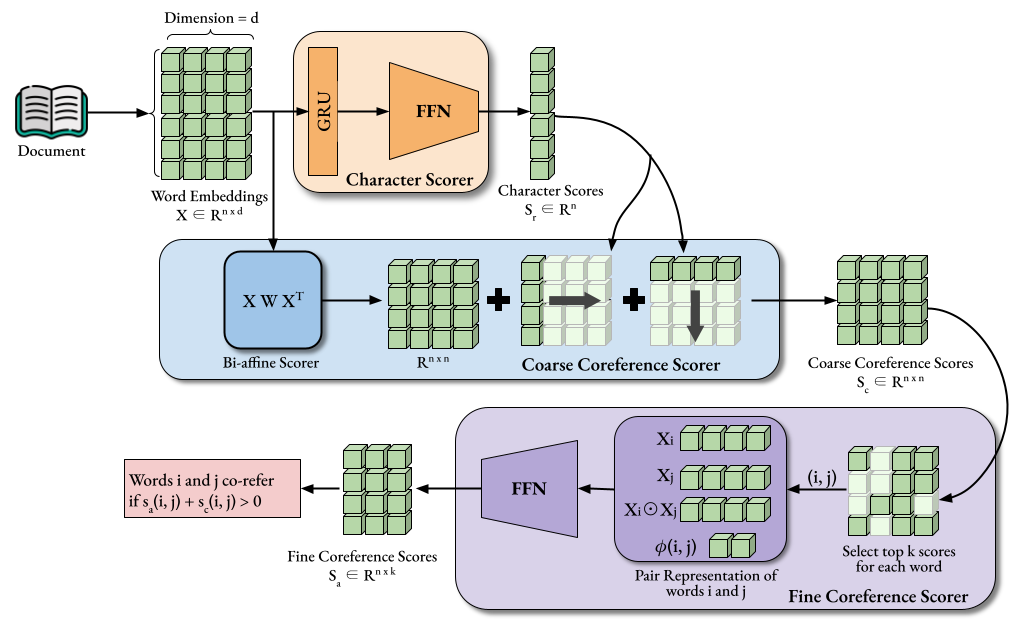 Character Coreference Resolution in Movie ScreenplaysSabyasachee Baruah, and Shrikanth NarayananIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023
Character Coreference Resolution in Movie ScreenplaysSabyasachee Baruah, and Shrikanth NarayananIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023Movie screenplays have a distinct narrative structure. It segments the story into scenes containing interleaving descriptions of actions, locations, and character dialogues.A typical screenplay spans several scenes and can include long-range dependencies between characters and events.A holistic document-level understanding of the screenplay requires several natural language processing capabilities, such as parsing, character identification, coreference resolution, action recognition, summarization, and attribute discovery. In this work, we develop scalable and robust methods to extract the structural information and character coreference clusters from full-length movie screenplays. We curate two datasets for screenplay parsing and character coreference — MovieParse and MovieCoref, respectively.We build a robust screenplay parser to handle inconsistencies in screenplay formatting and leverage the parsed output to link co-referring character mentions.Our coreference models can scale to long screenplay documents without drastically increasing their memory footprints.
@inproceedings{baruah-narayanan-2023-character, title = {Character Coreference Resolution in Movie Screenplays}, author = {Baruah, Sabyasachee and Narayanan, Shrikanth}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2023}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.findings-acl.654}, doi = {10.18653/v1/2023.findings-acl.654}, pages = {10300--10313}, }

2022
-
 Representation of professions in entertainment media: Insights into frequency and sentiment trends through computational text analysisSabyasachee Baruah, Krishna Somandepalli, and Shrikanth NarayananPLOS ONE, May 2022
Representation of professions in entertainment media: Insights into frequency and sentiment trends through computational text analysisSabyasachee Baruah, Krishna Somandepalli, and Shrikanth NarayananPLOS ONE, May 2022Societal ideas and trends dictate media narratives and cinematic depictions which in turn influence people’s beliefs and perceptions of the real world. Media portrayal of individuals and social institutions related to culture, education, government, religion, and family affect their function and evolution over time as people perceive and incorporate the representations from portrayals into their everyday lives. It is important to study media depictions of social structures so that they do not propagate or reinforce negative stereotypes, or discriminate against a particular section of the society. In this work, we examine media representation of different professions and provide computational insights into their incidence, and sentiment expressed, in entertainment media content. We create a searchable taxonomy of professional groups, synsets, and titles to facilitate their retrieval from short-context speaker-agnostic text passages like movie and television (TV) show subtitles. We leverage this taxonomy and relevant natural language processing models to create a corpus of professional mentions in media content, spanning more than 136,000 IMDb titles over seven decades (1950-2017). We analyze the frequency and sentiment trends of different occupations, study the effect of media attributes such as genre, country of production, and title type on these trends, and investigate whether the incidence of professions in media subtitles correlate with their real-world employment statistics. We observe increased media mentions over time of STEM, arts, sports, and entertainment occupations in the analyzed subtitles, and a decreased frequency of manual labor jobs and military occupations. The sentiment expressed toward lawyers, police, and doctors showed increasing negative trends over time, whereas the mentions about astronauts, musicians, singers, and engineers appear more favorably. We found that genre is a good predictor of the type of professions mentioned in movies and TV shows. Professions that employ more people showed increased media frequency.
@article{10.1371/journal.pone.0267812, doi = {10.1371/journal.pone.0267812}, author = {Baruah, Sabyasachee and Somandepalli, Krishna and Narayanan, Shrikanth}, journal = {PLOS ONE}, publisher = {Public Library of Science}, title = {Representation of professions in entertainment media: Insights into frequency and sentiment trends through computational text analysis}, year = {2022}, month = may, volume = {17}, url = {https://doi.org/10.1371/journal.pone.0267812}, pages = {1-37}, number = {5}, }

2021
-
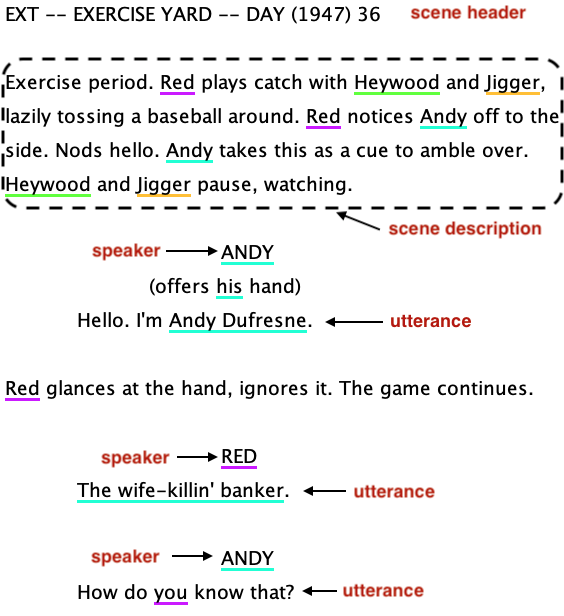 Annotation and Evaluation of Coreference Resolution in ScreenplaysSabyasachee Baruah, Sandeep Nallan Chakravarthula, and Shrikanth NarayananIn Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Aug 2021
Annotation and Evaluation of Coreference Resolution in ScreenplaysSabyasachee Baruah, Sandeep Nallan Chakravarthula, and Shrikanth NarayananIn Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Aug 2021Screenplays refer to characters using different names, pronouns, and nominal expressions. We need to resolve these mentions to the correct referent character for better story understanding and holistic research in computational narratology. Coreference resolution of character mentions in screenplays becomes challenging because of the large document lengths, unique structural features like scene headers, interleaving of action and speech passages, and reliance on the accompanying video. In this work, we first adapt widely-used annotation guidelines to address domain-specific issues in screenplays. We develop an automatic screenplay parser to extract the structural information and design coreference rules based upon the structure. Our model exploits these structural features and outperforms a benchmark coreference model on the screenplay coreference resolution task.
@inproceedings{baruah-etal-2021-annotation, title = {Annotation and Evaluation of Coreference Resolution in Screenplays}, author = {Baruah, Sabyasachee and Nallan Chakravarthula, Sandeep and Narayanan, Shrikanth}, booktitle = {Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.findings-acl.176}, doi = {10.18653/v1/2021.findings-acl.176}, pages = {2004--2010}, }

2017
- ICASSPA knowledge transfer and boosting approach to the prediction of affect in moviesSabyasachee Baruah, Rahul Gupta, and Shrikanth NarayananIn 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Aug 2017
Affect prediction is a classical problem and has recently garnered special interest in multimedia applications. Affect prediction in movies is one such domain, potentially aiding the design as well as the impact analysis of movies. Given the large diversity in movies (such as different genres and languages), obtaining a comprehensive movie dataset for modeling affect is challenging while models trained on smaller datasets may not generalize. In this paper, we address the problem of continuous affect ratings with the availability of limited in-domain data resources. We initially setup several baseline models trained on in-domain data, followed by a proposal of a Knowledge Transfer (KT) + Gradient Boosting (GB) approach. KT learns models on a larger (mismatched) data which are then adapted to make predictions on the data of interest. GB further updates these predictions based on models learnt from the in-domain data. We observe that the KT + GB models provide Concordance Correlation Coefficient values of 0.13 and 0.27 for valence and affect prediction on the continuous LIRIS ACCEDE dataset against best baseline prediction values of 0.12 and 0.11. Not only the KT + GB models improve the overall performance metrics, we also observe a more consistent model performance across movies of various genres.
@inproceedings{7952682, author = {Baruah, Sabyasachee and Gupta, Rahul and Narayanan, Shrikanth}, booktitle = {2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title = {A knowledge transfer and boosting approach to the prediction of affect in movies}, year = {2017}, volume = {}, number = {}, pages = {2876-2880}, doi = {10.1109/ICASSP.2017.7952682}, }